
Filtered AI
Tech Stack
A privacy-first AI gateway that de-identifies sensitive data before it ever reaches an LLM
Overview
Filtered (fltrd) is a privacy first AI gateway that de-identifies sensitive data before it ever reaches an LLM.
The Problem
Companies in legal, healthcare, and finance want to use AI — but can’t risk feeding confidential client data into tools like ChatGPT. Copy-pasting a contract into an AI prompt might violate GDPR, HIPAA, or client privilege. Yet the productivity gains of AI are too significant to ignore.
I led this project as a 3-person team at the ArolDev coding bootcamp — our final group project, delivered across two sprints in 3 weeks. Coming from a product and marketing background, I took on both the product ownership and development: scoping the vision, designing the architecture and database schema, and building alongside two fellow developers. It was the kind of project where you learn fast that the hardest part isn’t the code — it’s deciding what not to build when the clock is ticking.
The Solution
Filtered intercepts text before it hits the AI. Using Google Cloud’s DLP API, it automatically detects and masks personally identifiable information (names, dates, case numbers, etc.), then forwards the sanitized text to OpenAI for processing. The user gets AI-powered insights — without ever exposing sensitive data.
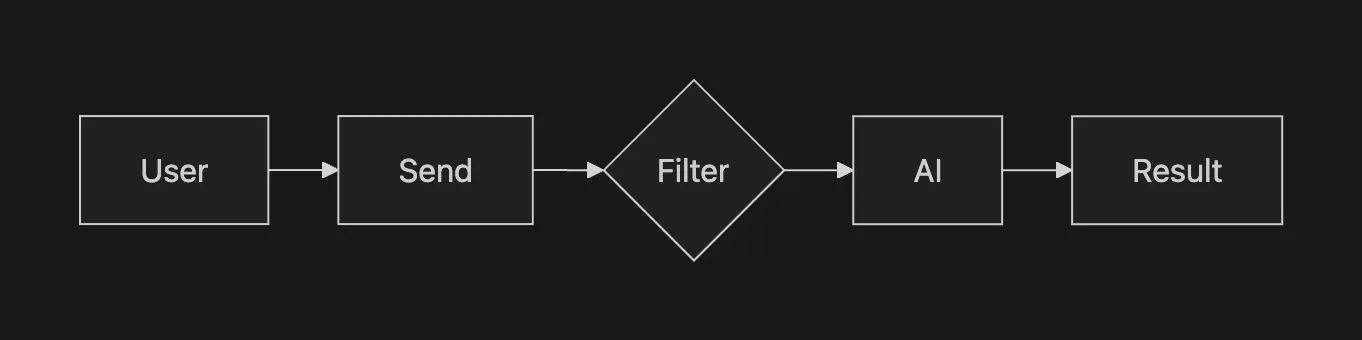
The flow is simple: write or paste your text → Filtered scans and redacts PII → a visual shield indicator confirms your data is clean → the sanitized prompt goes to the AI → you get your answer.
The DLP pipeline actually makes two separate calls to Google Cloud: first an inspect request to detect what sensitive entities exist, then a de-identify request to mask them. This two-step approach lets us show the user exactly what was found before transforming anything — giving them a chance to review and adjust before the data moves on.
Tech Stack
Frontend: React, TypeScript, Next.js, Tailwind CSS, shadcn/ui Backend: Next.js API routes, Auth0 APIs: Google Cloud DLP (de-identification), OpenAI (completions) Database: PostgreSQL via Prisma Design & Planning: Figma, Mermaid, Miro, Linear, Notion
Technical Challenges & Discoveries
The cost of not knowing. Every message has to be sent to the DLP API for inspection — even if it contains zero sensitive data. There’s no way to know upfront. This creates both a latency issue (the user waits for a check that might find nothing) and a cost issue (you’re paying per API call regardless). For a production version, this points toward eventually replacing the cloud API with a self-hosted NLP solution to keep both costs and latency under control.
UX trust gap. During early interaction testing, we discovered users were confused by the interface. The button to send a message looked the same as any AI chat — so users weren’t sure if their data had already been sent to the AI before filtering happened. This led us to add visual shield indicators (green = safe, orange = PII detected) to make the de-identification step explicit and build trust in the process. If you’re building anything that handles sensitive data, this is worth remembering: technical security means nothing if the user doesn’t feel secure.
Turn management at scale. To track conversation turns, we initially queried the database on every message to get the latest turn_id and increment it. This works fine for a POC, but we identified it as a bottleneck for production — too many round-trips to the DB. We designed (but didn’t fully implement) a client-side solution using React state to track turns locally, falling back to a DB query only when there’s a conflict.
Aggressive scoping. With 3 weeks and 3 people, we had to be ruthless. We cut file upload support, landing pages, role-based access, compliance dashboards, and custom redaction templates — focusing the first sprint purely on proving we could detect and display PII, and the second sprint on masking the data and connecting the AI pipeline. For anyone doing a bootcamp final project: scope like a product manager, not a dreamer. Your backlog will always be bigger than your bandwidth.
Status
The POC was built under bootcamp time constraints. Core features — PII detection, text redaction, and the OpenAI pipeline — were partially working at demo. I’m currently finishing the remaining functionality to bring it to a fully working state.